
ひさしぶりにSeleniumを使ってスクレイピングをしてみました。
実際には別の目的でツールを作ってみたのですが、
本記事では本サイトのTOPページに掲載しているブログカードのタイトルとリンクをCSVで出力してみたいと思います。
Seleniumの環境構築
以前も記事に環境構築方法を記載していますので、簡単に書きます。
- Pythonのインストール
- Seleniumのインストール
- テキストにコードを記載して.pyで保存
- ダブルクリックで実行といった感じです。
Windowsでユーザー名のフォルダ直下にpythonというフォルダを作成。
chromedriver.exeと.pyのファイルを置いて、そこから実行しています。

直接.pyを実行するとエラーで落ちて読み取れないことがあるので、下記のようなbatを噛ますとエラーが見やすいです。
sample.py
pauseちなみに2021年にSeleniumの仕様が変わってBYまわりのコマンドが変わっていますので注意。

Selenium│ページの内のブログカードのリンクを取得する方法
下記に記載したpythonコードを実行するとcsvファイルが出力。
csvファイルを開くとTOPページのブログカードのすべてのタイトルとリンクが取得できます。
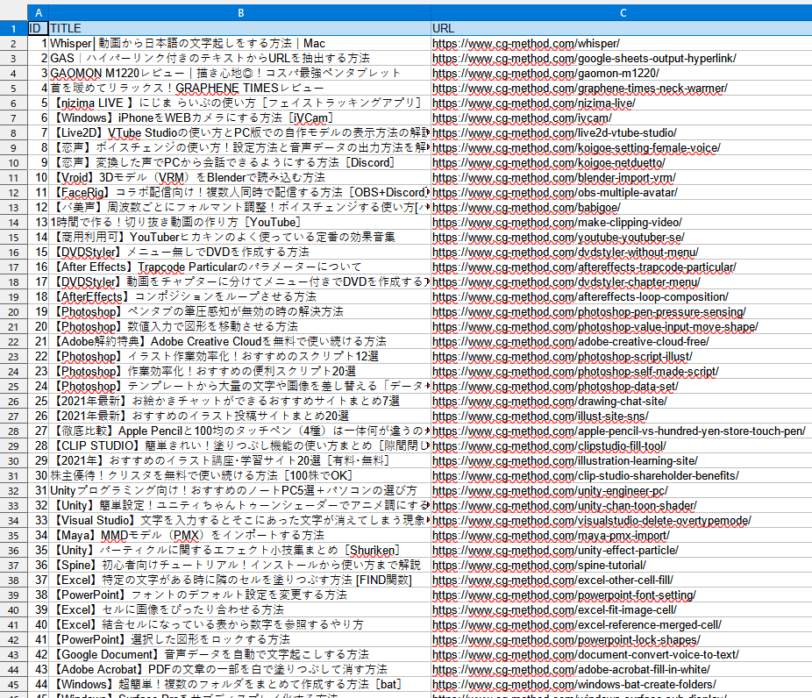
コードは以下の通り。
driver = webdriver.Chrome("C:/Users/suimin/python/chromedriver.exe",options=options)にchromedriver.exeのパスを記載。
site_url = "https://cg-method.com/"に調べたいページのURLを記載するだけです。
SWELLというWordPressテーマのソースコード、liを指定して、そのすべての要素を取得。
さらにそのリスト以下のタイトルとURLだけを取得。
それらを配列に格納して、csvに書き込んでいるだけです。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import csv
#オプション(エラーメッセージを非表示+ヘッドレスモード)
options = Options()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.use_chromium = True
options.add_argument("--headless")
driver = webdriver.Chrome("C:/Users/suimin/python/chromedriver.exe",options=options)
#CSVファイル
filename = "sample" + ".csv"
f = open(filename, "w", encoding="CP932", errors="ignore")
writer = csv.writer(f, lineterminator='\n')
#URL
site_url = "https://cg-method.com/"
driver.execute_script("window.open()")
driver.switch_to.window(driver.window_handles[-1])
driver.get(site_url)
#項目を記載
header = ["ID","TITLE","URL"]
writer.writerow(header)
#要素の取得
item = 1
elems= driver.find_elements(By.CLASS_NAME,"p-postList__item")
for elem in elems:
csvlist = []
csvlist.append(str(item))
title = elem.find_elements(By.CLASS_NAME,"p-postList__title")
link = elem.find_elements(By.CLASS_NAME,"p-postList__link")
csvlist.append(title[0].text)
csvlist.append(link[0].get_attribute("href") )
writer.writerow(csvlist)
item = item + 1
# 閉じる
f.close()
まとめ
以前のSeleniumの記事は特定のページにログインしてクリックするという内容でした。
自動で勤怠ボタンを押したりとかできる。。。
本記事はまじめにスクレイピングをしてみました。
たとえばデータベース系のサイトを作っている人の場合は、こういったツールを作って必要な情報を自動で取得。
あとは整形して、csvから自動記事投稿みたいなこともできます。
気になった方は是非、Seleniumを調べてみてください。






